Advertisement
Text-based information has always come with its own challenge: it's everywhere, but often disorganized. Whether it’s customer feedback, product reviews, survey responses, or internal documentation, the common issue is how to turn those scattered words into something organized, something useful. Large Language Models (LLMs) have made this a lot easier, thanks to their ability to interpret, segment, and extract meaning from language. The goal isn’t just understanding — it’s to shape that understanding into structured, reusable insights.
Here’s how LLMs can be used for that purpose across various kinds of text-heavy environments.

The first step in bringing order to unstructured content is to know what entities are being discussed. With LLMs, this doesn't require strict rule-based models anymore. The model can identify names of people, places, dates, quantities, organizations, and even product names, without any manually coded dictionary.
What makes it work well is context. LLMs understand that “Amazon” could be a company or a river depending on the sentence. They don’t just extract entities; they categorize them. Once extracted, these can be tagged and stored neatly — think columns like “Company Name,” “Location,” “Date Mentioned,” and so on.
Knowing entities isn’t always enough. What connects them is often just as important. LLMs can identify relationships between entities, whether it’s “Person A works at Company B” or “Event X happened in City Y.” These connections turn isolated information into a network.
This is especially useful for building knowledge graphs or populating fields in databases that require links between concepts. Instead of manually linking a complaint to a product issue or matching a person to their role, the model can infer it straight from the text.
Sometimes you don’t need exact words. You need the tone behind them. LLMs are good at figuring out if someone is happy, frustrated, or uncertain, even when it’s not directly stated. This is where sentiment classification comes in — but modern models can take it one step further by identifying intent.
A customer saying “I guess I’ll have to return it” is showing dissatisfaction and a probable action. You can’t rely on keyword matching for this. LLMs can capture nuance and output clear, structured values — for example, columns marked “Sentiment: Negative” or “Intent: Return Request.”
When you don’t need the full content, just the main idea, summarization comes in. LLMs can shrink paragraphs into short, factual bullets that retain the core information. Unlike classic summarizers that just trim content, LLMs understand what’s relevant.
This means you can turn a lengthy email thread into a “Topic,” “Action Required," "Deadline" format. Or take customer support logs and break them down into "Issue Type," "Steps Taken," "Current Status." The point isn't just shortening — it's refitting the text into predefined fields.
When processing large volumes of text, understanding which category each chunk belongs to helps you break it down for analysis. LLMs can read through pages and label segments into themes — even overlapping ones — based on how topics flow.
Whether it's a company analyzing internal reports or researchers organizing open-ended survey responses, this kind of classification lets users filter and group data by subject. You end up with sorted folders of meaning, not just folders of files.
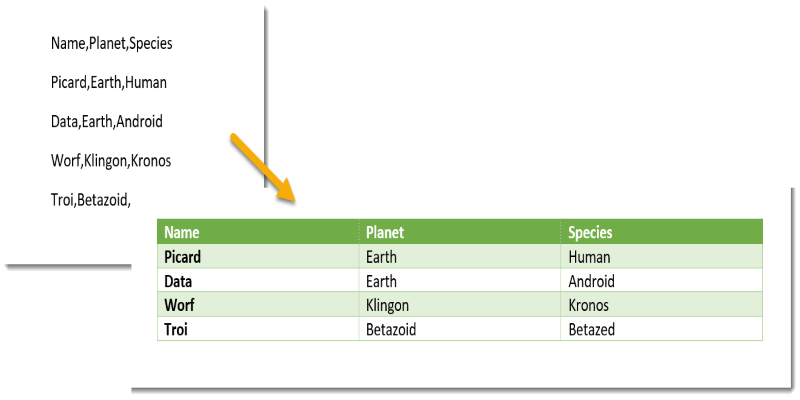
LLMs can recognize tabular patterns inside unstructured text. For example, an email might say “We sold 45 units in New York and 32 in Boston,” and the model can return a row-by-row structure: Location | Units Sold.
This isn’t just filling in blanks — it’s understanding that values and attributes are being presented informally, then converting them into formal, tabular formats that spreadsheets or databases can work with. It’s a practical tool when the source material wasn’t built for data entry but still contains data worth keeping.
Sometimes you want to pull specific information out of a body of text, not just general entities, but fields tied to your internal logic. LLMs allow prompts that mimic forms or templates. You feed in the schema — maybe something like "Candidate Name," "Years of Experience," "Preferred Location" — and let the model extract values directly from a resume or profile.
This doesn’t require retraining the model. It’s prompt-driven, so you adapt the instruction, and the output aligns with your system’s structure. You’re not just parsing the document — you’re turning it into a pre-filled form.
Meeting transcripts, support chats, and interviews — these tend to be long and free-flowing. What you often want from them are decisions, next steps, or commitments. LLMs can go through an entire conversation and pull out structured data points like "Task Owner," "Due Date," "Priority," and "Issue Discussed."
This isn’t a keyword search. It’s about finding commitments hidden in casual language. A phrase like “Let’s revisit this next Thursday” becomes a time-stamped follow-up. This is especially helpful for automating meeting minutes or CRM updates.
When you don't have a fixed schema or training data, you can still guide the model with examples. Show it a few sample inputs and desired outputs, and it can mimic the structure. This is useful when you have flexible formats or need to extract data for a one-off task.
If you’re working on legal contracts, medical notes, or policy drafts, and want the model to extract or rewrite content into structured tables, giving a few examples up front is often enough to get consistent results.
There's no single method for converting text into structured output. The strength of LLMs is that they can shift depending on the need, from pulling names and relationships to reshaping dialogue into data rows. Whether you need summaries, categories, or spreadsheets, you can find a path from plain text to structured form without rewriting everything manually. The trick is knowing what shape you want your insights to take — and then letting the model handle the translation.
Advertisement

How to create an AI voice cover using Covers.ai with this simple step-by-step guide. From uploading audio to selecting a voice and exporting your track, everything is covered in detail

Discover multilingual LLMs: how they handle 100+ languages, code-switching and 10 other things you need to know.

Learn different methods to calculate the average of a list in Python. Whether you're new or experienced, this guide makes finding the Python list average simple and clear
Want to turn messy text into clear, structured data? This guide covers 9 practical ways to use LLMs for converting raw text into usable insights, summaries, and fields

Learn seven methods to convert a string to an integer in Python using int(), float(), json, eval, and batch processing tools like map() and list comprehension
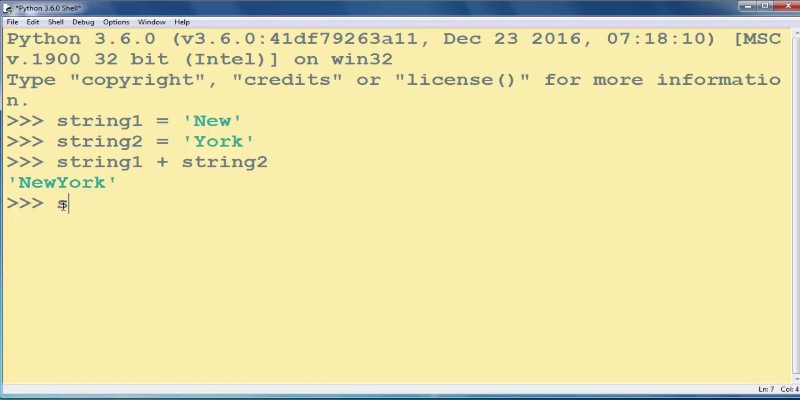
How to add strings in Python using 8 clear methods like +, join(), and f-strings. This guide covers everything from simple concatenation to building large text efficiently
Learn 8 effective methods to add new keys to a dictionary in Python, from square brackets and update() to setdefault(), loops, and defaultdict

Create user personas for ChatGPT to improve AI responses, boost engagement, and tailor content to your audience.

Ask QX by QX Lab AI is a multilingual GenAI platform designed to support over 100 languages, offering accessible AI tools for users around the world

Compliance analytics ensures secure data storage, meets PII standards, reduces risks, and builds customer trust and confidence

Stay informed with the best AI news websites. Explore trusted platforms that offer real-time AI updates, research highlights, and expert insights without the noise
Explore effective ways for scatter plot visualization in Python using matplotlib. Learn to enhance your plots with color, size, labels, transparency, and 3D features for better data insights