Advertisement
Data isn't just stored anymore—it's mapped, linked, and traced. Whether you're managing a company’s customer list or mapping relationships on a social network, how you store and connect data matters. That’s where the choice between relational and graph databases shows up. One uses rows and tables; the other builds nodes and connections.
The difference goes deeper than just layout—it changes how fast you can ask questions, how you grow your data, and how easy it is to adjust. This article breaks it down in plain language. You don’t need a computer science degree to get it.
A relational database stores data in tables, analogous to a spreadsheet. Each table contains rows (records) and columns (fields), and each table can reference other tables with a system of keys. Relational databases have a strict schema, so the shape of your data must be declared before entering data into it.
Well-known examples are MySQL, PostgreSQL, and Oracle. They are mature and reliable. They appear in everything from online banking systems to websites of e-commerce businesses. They excel when the data is highly structured, doesn't need frequent changes, and can be organized tidily into tables.
SQL (Structured Query Language) is utilized in queries for relational databases. SQL excels at dealing with operations such as filtering, sorting, and joining tables, particularly if the data model is predictable.
A graph database works differently. Instead of tables, it uses nodes and edges. Nodes represent entities (like a person, product, or location), and edges represent the relationships between them. It’s a more natural way to model complex connections.
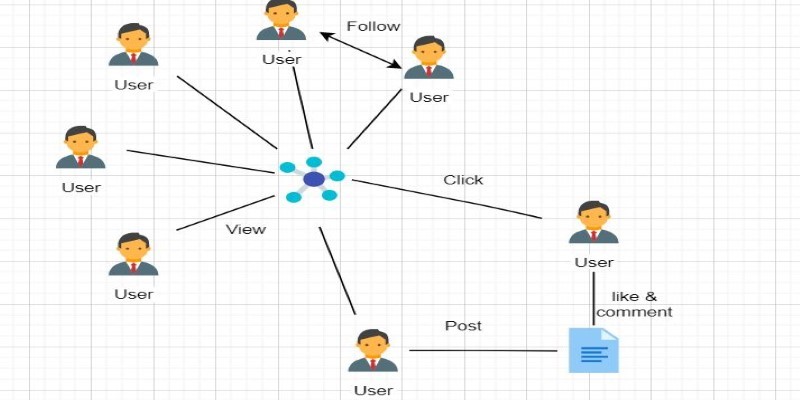
The most common graph database is Neo4j, though others like Amazon Neptune and ArangoDB are gaining traction. These databases are often used for problems where relationships between data points matter more than the data itself. Think social networks, recommendation systems, or fraud detection.
Graph databases use their query languages—Neo4j, for example, uses Cypher. These languages are built to travel across relationships quickly and efficiently, which is harder to do in relational systems.
Relational databases model relationships using foreign keys and join tables. For example, a customer order system might need one table for customers, another for orders, and a third to link them. While this works, it can become messy with deep or many-to-many relationships.
In contrast, a graph database puts relationships front and center. If one person knows five others, you draw a line (edge) from one node to the next. This structure makes it easy to follow paths and map out complex networks. You don’t need to keep writing joins—relationships are a first-class citizen.
So when your data is heavily interconnected—like friends of friends, or shared purchases across users—graph databases are easier to model and maintain.
In relational databases, querying across multiple tables involves JOIN operations. JOINs can become slow as more tables are linked or as data grows. Finding indirect connections (e.g., all people connected to a person via multiple hops) is slow and not natural in SQL.
A graph database is optimized for this kind of traversal. Want to find all users two steps away from a specific node? That’s a basic graph operation. Traversal performance doesn't degrade the same way as it does in relational systems because the connections are built-in.
That said, relational databases are still better when you're doing traditional queries: totals, averages, filters, and groupings. They’re fast, simple, and precise for those tasks.
Relational databases are fast with normalized data, especially when indexes are used well. But once you start adding deep joins and large datasets with many relationships, performance starts to drop. Scaling relational databases often means adding more hardware vertically (stronger machines).

Graph databases scale differently. They handle highly connected data better and can scale horizontally in certain setups. The performance remains stable even as relationships increase. That makes them better suited for large networks where speed and relationship depth are important.
Still, for simple or flat datasets, a relational system might outperform a graph database. It depends on the structure of the workload.
Relational databases require a strict schema. Every table needs to be defined ahead of time. If you want to add a new column or restructure data, you often need to run migrations, which can be slow or risky on big datasets.
Graph databases offer more flexibility. You can add new types of nodes or edges without redesigning everything. This is helpful in fast-changing environments, like startups or research projects, where your understanding of the data may evolve.
Flexibility comes at a cost, though. Without a fixed schema, you need to be disciplined to avoid chaos. But in general, a graph database lets you grow and adapt faster.
Relational databases are the backbone of business systems. They’re used in:
When data is predictable, like in financial transactions or sales records, relational systems are the standard.
Graph databases are more niche but growing fast. Common use cases include:
Anywhere relationships matter more than rows, a graph database fits better. Think of LinkedIn showing mutual connections or Netflix suggesting what to watch next based on patterns, not just rows of numbers.
Some companies even use both together. For example, storing general data in a relational system and building a separate graph layer for relationship-heavy queries.
Relational databases have earned their place in the data world with consistency, structure, and solid performance in well-organized systems. Graph databases offer a newer, more flexible way to think about and query data, especially when connections matter more than values in a table. There's no one-size-fits-all answer in the relational database vs graph database debate. It depends on the shape of your data, the questions you want to ask, and how often those questions change. If your data looks like a spreadsheet, stick with relational. If your data looks like a web of connections, try a graph database. Either way, understanding both helps you choose better tools for better systems.
Advertisement

Looking for quality data science blogs to follow in 2025? Here are the 10 most practical and insightful blogs for learning, coding, and staying ahead in the data world

How to create an AI voice cover using Covers.ai with this simple step-by-step guide. From uploading audio to selecting a voice and exporting your track, everything is covered in detail
How to use Matplotlib.pyplot.hist() in Python to create clean, customizable histograms. This guide explains bins, styles, and tips for better Python histogram plots

Stay informed with the best AI news websites. Explore trusted platforms that offer real-time AI updates, research highlights, and expert insights without the noise
Explore effective ways for scatter plot visualization in Python using matplotlib. Learn to enhance your plots with color, size, labels, transparency, and 3D features for better data insights

Learn how logic gates work, from basic Boolean logic to hands-on implementation in Python. This guide simplifies core concepts and walks through real-world examples in code

Looking for the best AI resume builders? Check out these 10 free tools that help you craft professional resumes that stand out and get noticed by employers

Anthropic faces a legal battle over AI-generated music, with fair use unlikely to shield the company from claims.

Learn different methods to calculate the average of a list in Python. Whether you're new or experienced, this guide makes finding the Python list average simple and clear

Looking to turn your images into stickers? See how Replicate's AI tools make background removal and editing simple for clean, custom results

Oyster, a global hiring platform, takes a cautious approach to AI, prioritizing ethics, fairness, and human oversight
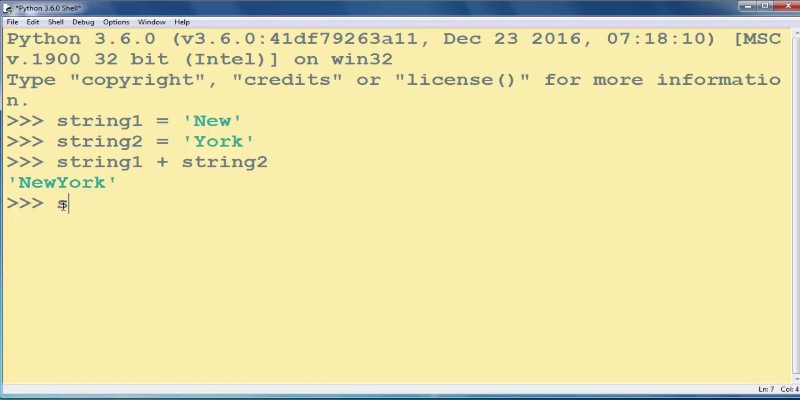
How to add strings in Python using 8 clear methods like +, join(), and f-strings. This guide covers everything from simple concatenation to building large text efficiently