Advertisement
AI models function primarily through internal settings known as artificial intelligence parameters. Like weights and biases, these inner values let a model anticipate and change as it gathers new data. From hyperparameters specified before training starts to model parameters that change throughout training, each type is essential in raising accuracy and efficiency. Regularizing parameters ensures the model's generalization to fresh data by preventing overfitting.
Maximizing performance and avoiding frequent problems like overfitting or slow training depends on correctly setting these parameters. The model develops its parameters to reduce mistakes and raise prediction accuracy as it trains. Anyone working with artificial intelligence has to understand and modify these values since they directly affect the model's ability to address practical issues.

AI parameters are internal values a model picks from data during training. These principles direct the model's handling of inputs to provide judgments or forecasts. Weights and biases are the most often used artificial intelligence values since they change the impact of every input on the output. The model changes these settings by gathering additional data to lower mistakes and raise accuracy. Both straightforward models like linear regression and sophisticated models like deep neural networks depend on parameters.
They are automatically optimized by training techniques such as gradient descent rather than being manually chosen. The model's size and structure determine the parameters' overall count. A model with additional parameters can capture additional patterns, but if improperly controlled, it runs the danger of overfitting. Building accurate, effective artificial intelligence systems depends on an awareness of and control over parameters. Artificial intelligence parameters define the learning of the model and directly influence its performance on certain tasks.
Artificial intelligence models use three major parameters. These are regularization, hyperparameter, and model parameters. Everybody is rather crucial for performance and training.
Determining the performance of an AI model depends much on parameters. Directly affecting the capacity of the model to learn and produce accurate predictions are the amount and quality of parameters. Too few parameters in a model could make it difficult to grasp intricate data trends, affecting performance. Conversely, too many parameter models can overfit the training set. They thus excel in training data but fail to generalize to fresh, unprocessed data.
Achieving the best performance depends on striking the proper balance of parameters. Furthermore, aggravating the computing cost of the model and slowing down the training process are too many constraints. Changing parameters during training improves the model's data interpretation and decreases mistakes. Correctly set parameters are crucial for the success of every artificial intelligence application since they enable the model to train effectively and generate more accurate, consistent outputs.

Gradient descent is used in training parameters wherein the model modifies its internal values to raise performance. The model first guesses starting from the present parameters. It then contrasts its forecasts with the real numbers to find the inaccuracy or loss. The tweaks are directed by this mistake. The model uses algorithms like gradient descent to adjust the loss by small steps so the parameters are adjusted. The learning rate shapes the size of these phases.
If the learning rate is too high, the model may overshoot the ideal parameters; if it is too low, it can take too long to get to them. Over several epochs, this process is repeated, and the model makes little enhancements every time. The model improves in making predictions as it gathers more data and modulates its parameters. In this sense, parameters are progressively tuned to minimize mistakes and raise the model's accuracy.
Usually, tweaking AI settings starts the process of improving its performance. More accurate predictions and more effective learning of the model depend on better parameters. Tuning model parameters like weights and biases comes first to guarantee the model adapts them suitably throughout training. It facilitates the capture of key data patterns in the model. Then, pay close attention to hyperparameters—values established before training starts.
The learning rate, batch size, and number of layers—among other values—can significantly impact the model's learning ability. Selecting the correct mix increases accuracy and speeds training. Additionally, fine-tuned parameters should be regularization parameters to avoid overfitting, preventing the model from performing well on training data but poorly on unseen data. L1 and L2 regularization are two methods that simplify the model, enhancing its generalizing ability.
In conclusion, the performance and accuracy of a model are much shaped by artificial intelligence parameters. Control of model, hyper, and regularization parameters can help maximize learning and avoid overfitting problems. The correct balance guarantees the model's performance on unseen data and training, improving its generalizing capacity. Frequent fine-tuning of key parameters during training enables constant development, producing more dependable and effective artificial intelligence systems. Building successful, high-performance AI models that can efficiently address real-world problems depends on knowing how to change and hone parameters.
Advertisement

Compliance analytics ensures secure data storage, meets PII standards, reduces risks, and builds customer trust and confidence

Learn how to convert strings to JSON objects using tools like JSON.parse(), json.loads(), JsonConvert, and more across 11 popular programming languages

Jio Brain by Jio Platforms brings seamless AI integration to Indian enterprises by embedding intelligence into existing systems without overhauls. Discover how it simplifies real-time data use and smart decision-making

Oyster, a global hiring platform, takes a cautious approach to AI, prioritizing ethics, fairness, and human oversight
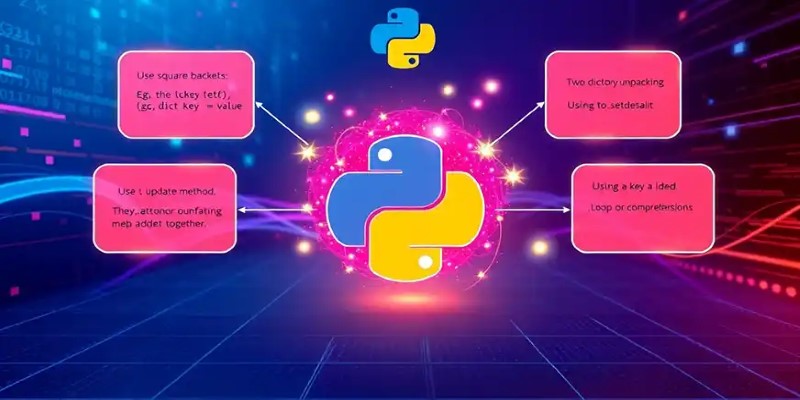
Learn 8 effective methods to add new keys to a dictionary in Python, from square brackets and update() to setdefault(), loops, and defaultdict

Want to build a dataset tailored to your project? Learn six ways to create your own dataset in Python—from scraping websites to labeling images manually
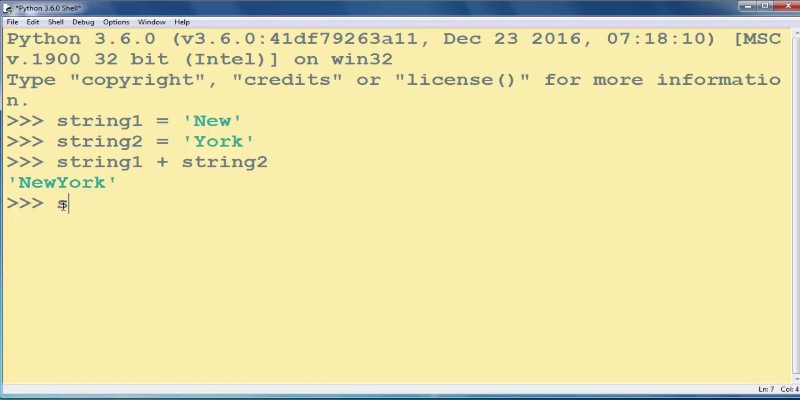
How to add strings in Python using 8 clear methods like +, join(), and f-strings. This guide covers everything from simple concatenation to building large text efficiently

Learn how the zip() function in Python works with detailed examples. Discover how to combine lists in Python, unzip data, and sort paired items using clean, readable code
Want to turn messy text into clear, structured data? This guide covers 9 practical ways to use LLMs for converting raw text into usable insights, summaries, and fields

Looking to turn your images into stickers? See how Replicate's AI tools make background removal and editing simple for clean, custom results

Discover multilingual LLMs: how they handle 100+ languages, code-switching and 10 other things you need to know.

Anthropic faces a legal battle over AI-generated music, with fair use unlikely to shield the company from claims.